文章目录
- 前言
- 一.使用库中vector常用接口
- 二.vector的模拟实现
- 总结
前言
上一篇我们讲解了STL中的string的使用和模拟实现,这次我们就来讲解STL中的vector,vector相对于string来说模拟实现会难一些,难点在于迭代器失效问题和深浅拷贝问题。
首先介绍一下vector:
一、使用库中的vector的常用接口
1.首先是对象的创建,使用vector必须确定类型否则会报错,push_back就是尾插一个数据,size()是求一个对象的长度与string相同,我们实现过string知道string会多开一个空间放\0,但是vector的capacity就是实际空间。
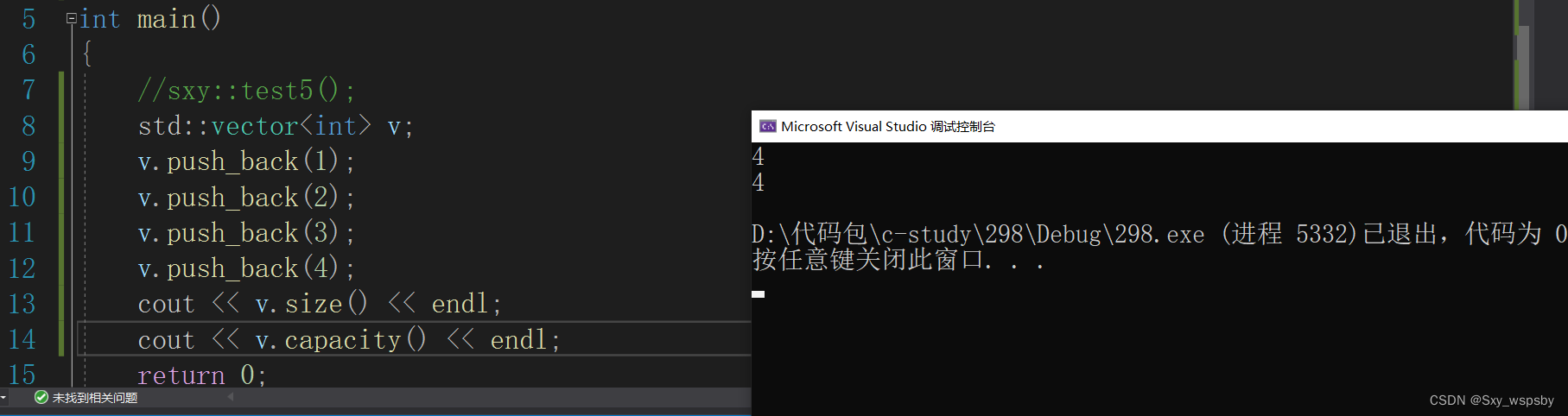
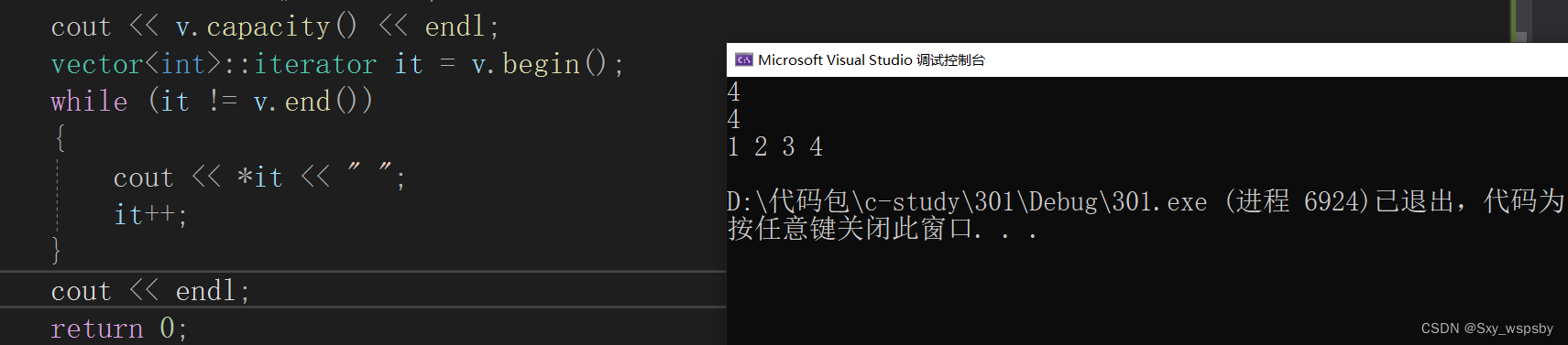
2.vector的迭代器与string的使用方法相同,如下图:
3.reserve与string中的一样,只开空间改变capacity
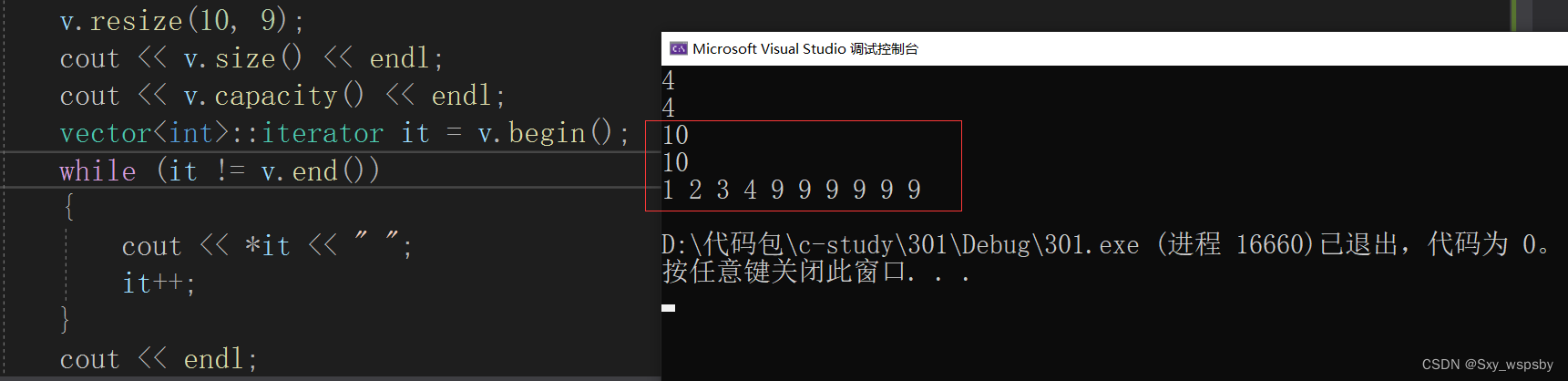
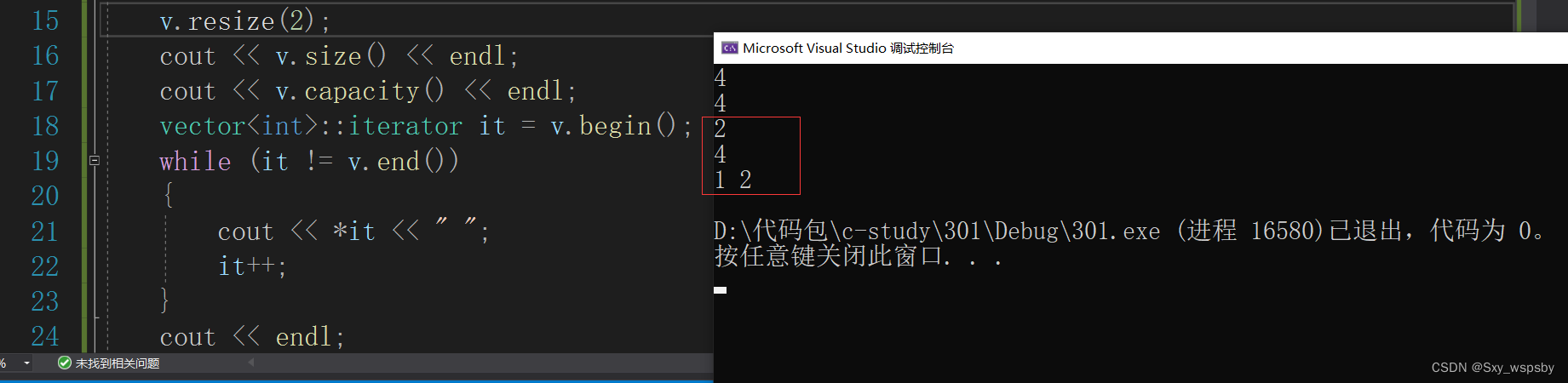
 4.resize与string一样,改变空间并且初始化,如果空间小于原先的size就删除多余的数据:
4.resize与string一样,改变空间并且初始化,如果空间小于原先的size就删除多余的数据:
 5.pop_back是尾删
5.pop_back是尾删
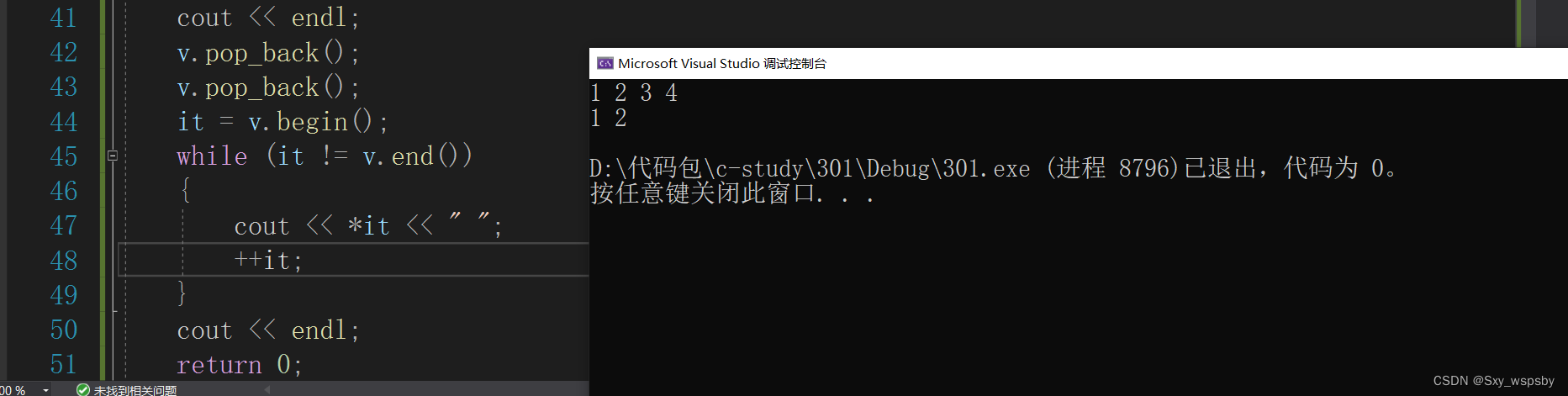
6.insert 通常是配合find去使用

- int main()
- {
- vector<int> v;
- v.push_back(1);
- v.push_back(2);
- v.push_back(3);
- v.push_back(4);
- vector<int>::iterator pos = find(v.begin(), v.end(), 2);
- if (pos != v.end())
- {
- v.insert(pos, 50);
- }
- vector<int>::iterator it = v.begin();
- while (it != v.end())
- {
- cout << *it << " ";
- it++;
- }
- cout << endl;
- return 0;
- }

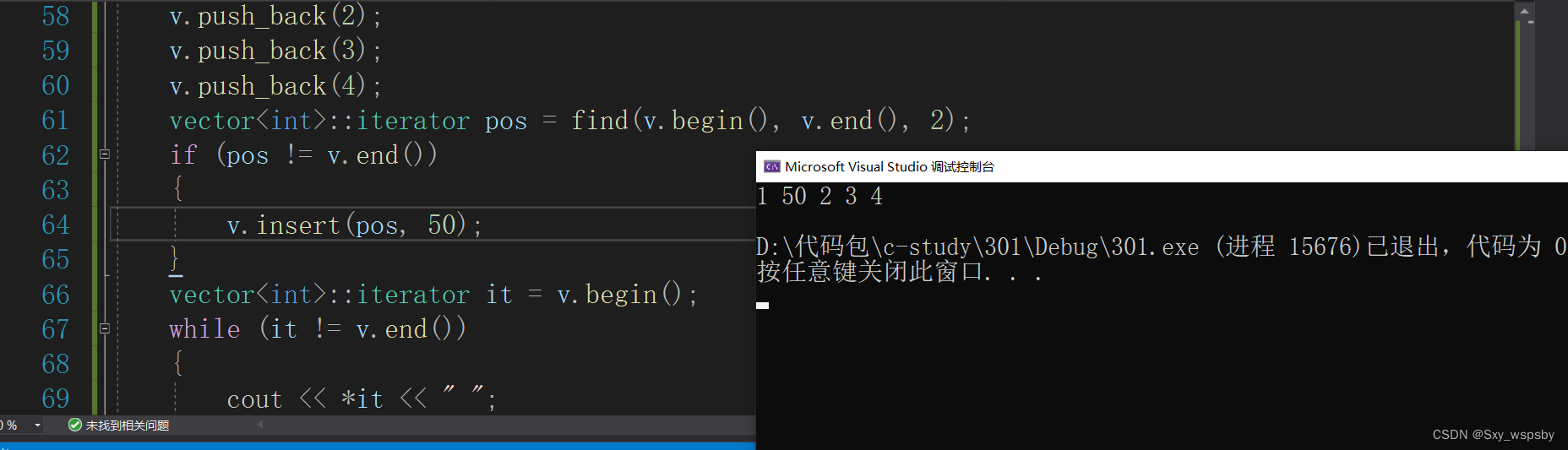
上面我们是用find函数找到2的位置,然后将50插入到2的位置。
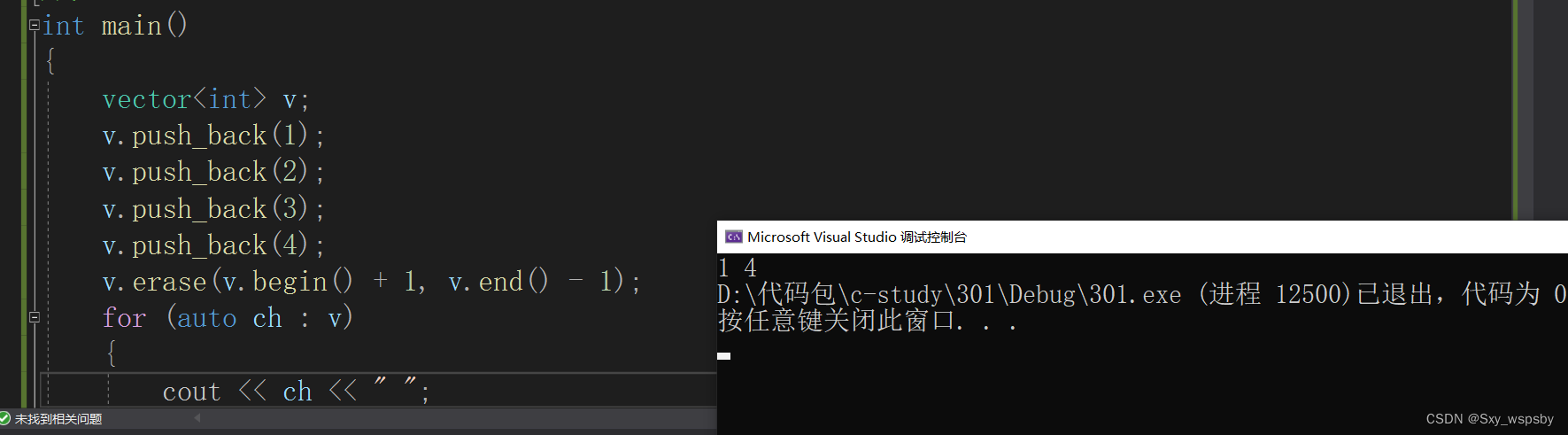
7.erase是删除一个数据,与insert一样要搭配使用
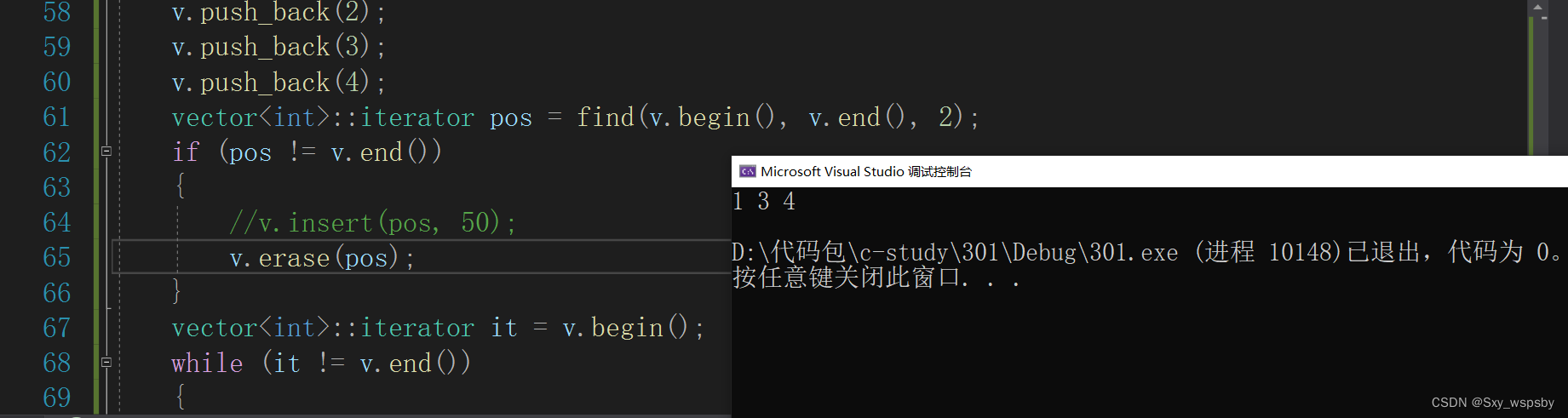
我们修改刚刚的代码将插入改为删除,就成功删除了2这个数据,当然也可以删除多个需要迭代器实现:
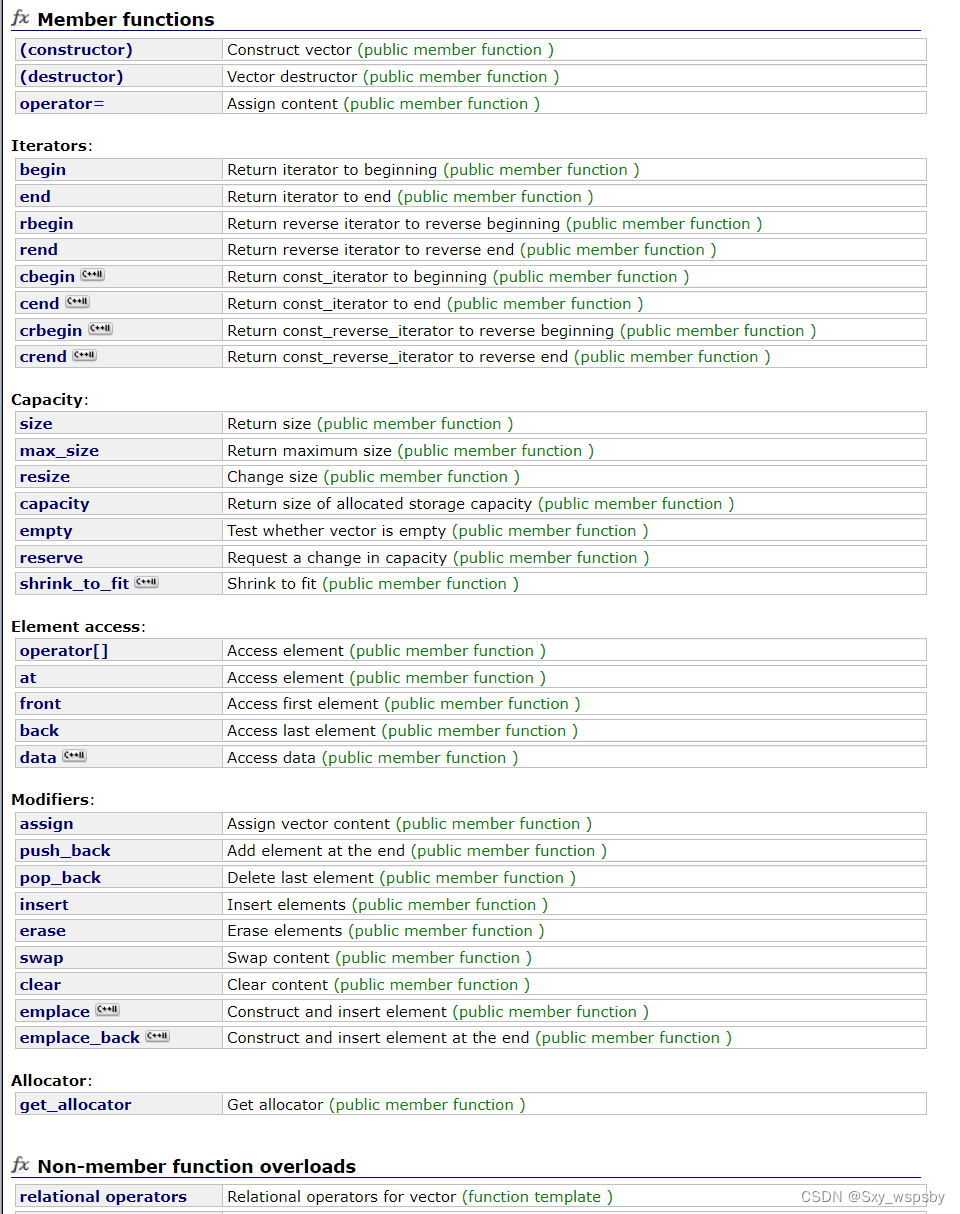
以上就是一些常用的vector的接口,vector的接口不再像string那样太冗余,我们可以通过下图看到库中vector的接口也不是很多:
二、vector的模拟实现
vector的模拟实现与string一样,我们都会按照库中的源码进行实现但也不是完全的模仿源码,因为源码的封装性太强而我们并不需要像源码那样封装。
首先源码中的开头是禁止有人将源码售卖等并且有改动的话需要公开,对于源码来说我们只看最核心的那部分,至于其他的编译条件语句什么的我们并不关心。
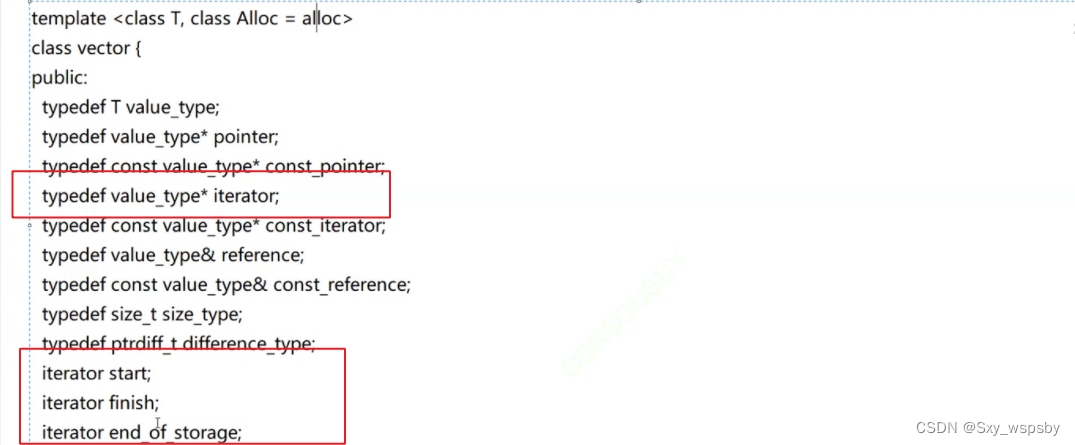
上图是源码中的成员变量,最重要的是iterator,这里还不容易看出来,我们再看下一张图:

相信大家已经看出来了吧,实际上库中的vector底层就是原生指针,只不过通过封装将指针名重命名为value_type,然后又将指针重命名为iterator,我们可以看到一共三个指针,_start,_finish,_end_of_storage通过名称我们可以辨认它们三个作用,再结合size()和capacity()的实现我们就能知道start指向起始位置,finish指向最后一个数据的后一个位置,因为只有这样指针相减才是size大小,而end很明显就是容量了。如下图所示:

知道了底层是如何实现的我们就可以来模拟实现了,首先为了防止命名冲突我们将要模拟的vector写到我们自己的命名空间里。
- namespace sxy
- {
- template<class T>
- class vector
- {
- public:
- typedef T* iterator;
- private:
- iterator _start;
- iterator _finish;
- iterator _end_of_storage;
- };
- }
在这里我们用模板的目的是创造一个任意类型的指针,因为我们的vector是可以放任意类型的。首先我们typedef一个iterator来代表T*的指针,然后私有成员写出和源码一样的三个成员变量。
然后我们先写出size()和capacity()函数,如下:
- size_t size() const
- {
- return _finish - _start;
- }
- size_t capacity() const
- {
- return _end_of_storage - _start;
- }
我们之前说过,当函数内不涉及修改成员变量时就加上const,这样普通对象和const对象就都能调用这个函数了。我们在实现一个判断是否为空的函数:
- bool empty() const
- {
- return _start == _finish;
- }
要判断是否为空很简单,只需要看start是否等于finish,因为如果有数据finish会指向最后一个数据的下一个位置。
然后我们再实现一下[]符号的重载,因为遍历数组最方便的就是[]:
- T& operator[](size_t pos)
- {
- assert(pos < size());
- return _start[pos];
- }
- const T& operator[](size_t pos) const
- {
- assert(pos < size());
- return _start[pos];
- }
需要注意的是我们返回的对象是T类型的,前面我们说过vector是一个模板任何类型都能够使用所以我们不能只单单返回一个int类型,【】访问需要实现const版本的,因为有的静态对象也需要访问数据,这里我们在string中都讲解过就不再赘述。
我们先实现一个简单的构造函数,能完成初始化指针就可以:
- vector()
- :_start(nullptr)
- ,_finish(nullptr)
- ,_end_of_storage(nullptr)
- {
-
- }
初始化我们能在初始化列表初始化就在初始化列表初始化。
下面开始进入正题了,我们先实现push_back接口,对于这个接口我们需要考虑的是扩容问题:
- void push_back(const T& x)
- {
- if (_finish==_end_of_storage)
- {
- reserve(capacity() == 0 ? 4 : 2 * capacity());
- }
- *_finish = x;
- ++_finish;
- }
当finish等于end_of_storage时就需要扩容了,扩容的时候要注意不能直接扩容2倍的空间,因为刚开始capacity是有可能为0的,所以我们用一个三目操作符来解决这个问题,当容量为0时就开4个空间,否则就是2倍空间。当成功开完空间后我们就将要插入的值放入finish的位置然后让finish自加。下面我们来讲解扩容的问题:
- void reserve(size_t n)
- {
- if (n > capacity())
- {
- size_t sz = size();
- T* tmp = new T[n];
- if (_start)
- {
- for (size_t i = 0; i < sz; i++)
- {
- tmp[i] = _start[i];
- }
- delete[] _start;
- }
- _start = tmp;
- _finish = _start + sz;
- _end_of_storage = _start + n;
- }
- }
在我们实现string的时候扩容什么的接口我们可以用memcpy等函数直接搞定那是因为string中的类型是char是内置类型,而vector是一个针对任意类型的模板,如果我们还用memcpy这样的浅拷贝的话是一定会出问题的,比如vector<string>里面存放的是string,如果用memcpy的话就导致vector里的每一个string对象都指向同一块空间,如下图:
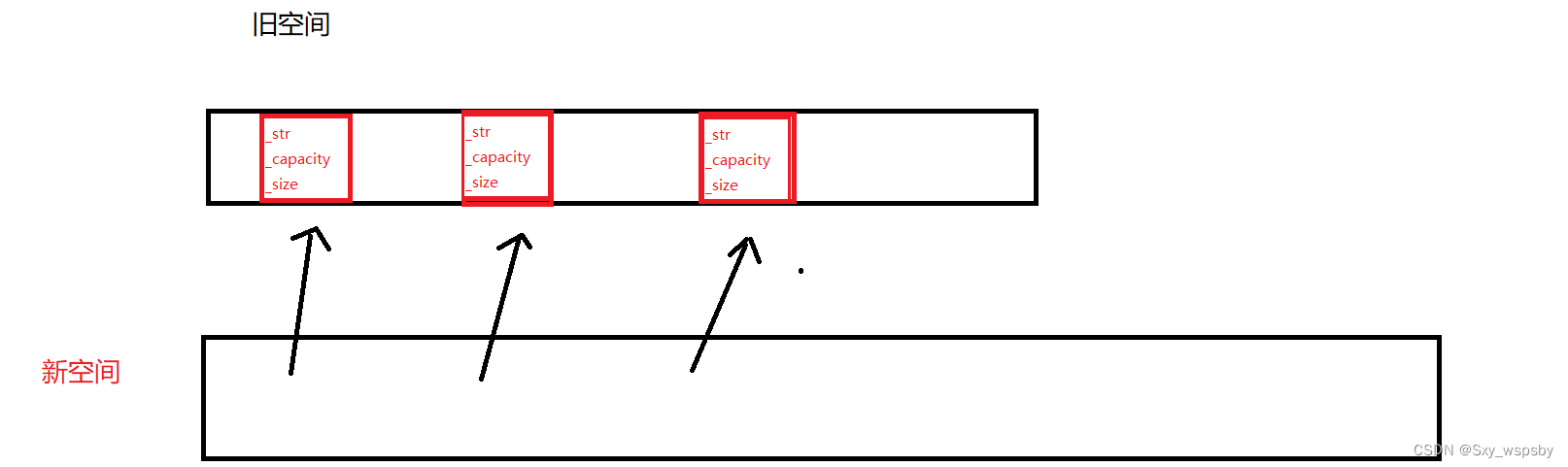
这样在我们析构的时候释放空间就会将原来的空间释放两次程序就崩溃了,更具体的深浅拷贝问题我们在文章的最后面会更详细的讲解, 现在的实现大家只需要记住让对象一个一个去赋值即可。
reserve的实现与string中的一样,只有在重新开的空间大于原先的空间的时候我们才进行扩容,先用一个T类型的指针tmp开一个和原先capacity一样的空间,如果原先是有空间的不是空指针我们就将原先空间的值依次赋值给新空间,然后再将旧空间释放掉,在这里大家会有疑问,为什么要用一个变量提前记录size()的大小呢?我们画个图给大家解释一下:
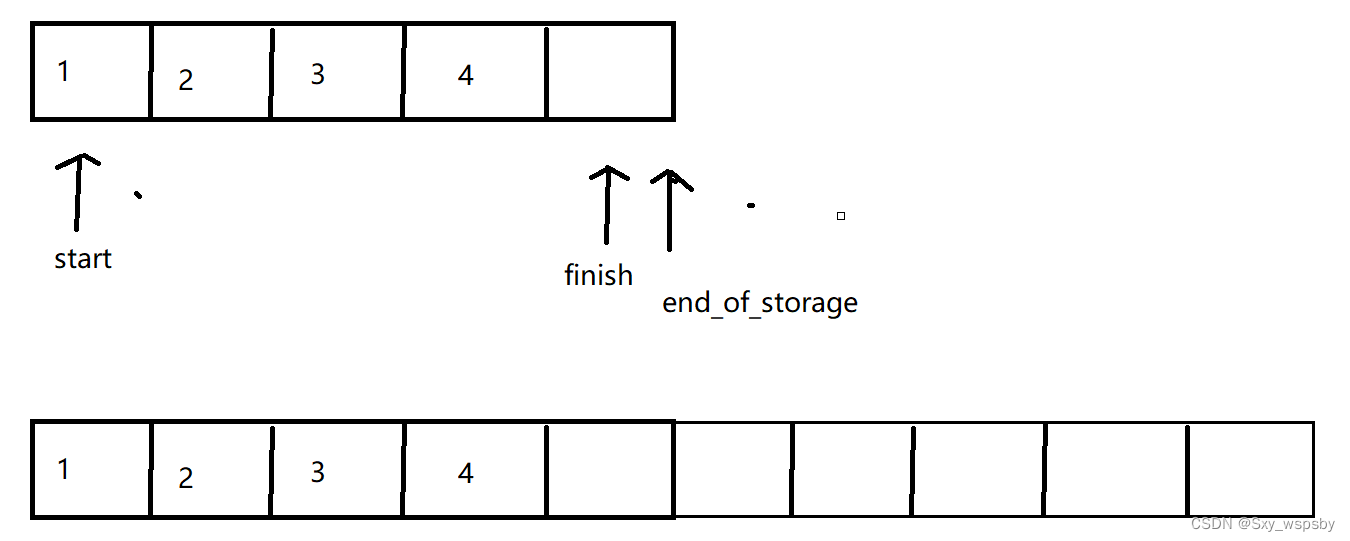
我们实现size()函数的时候使用finish-start的,而当我们开新空间后,size()的计算还是用旧空间上的指针来计算的,当我们将新空间给start后,这个时候的size()是计算不出来的如下图:
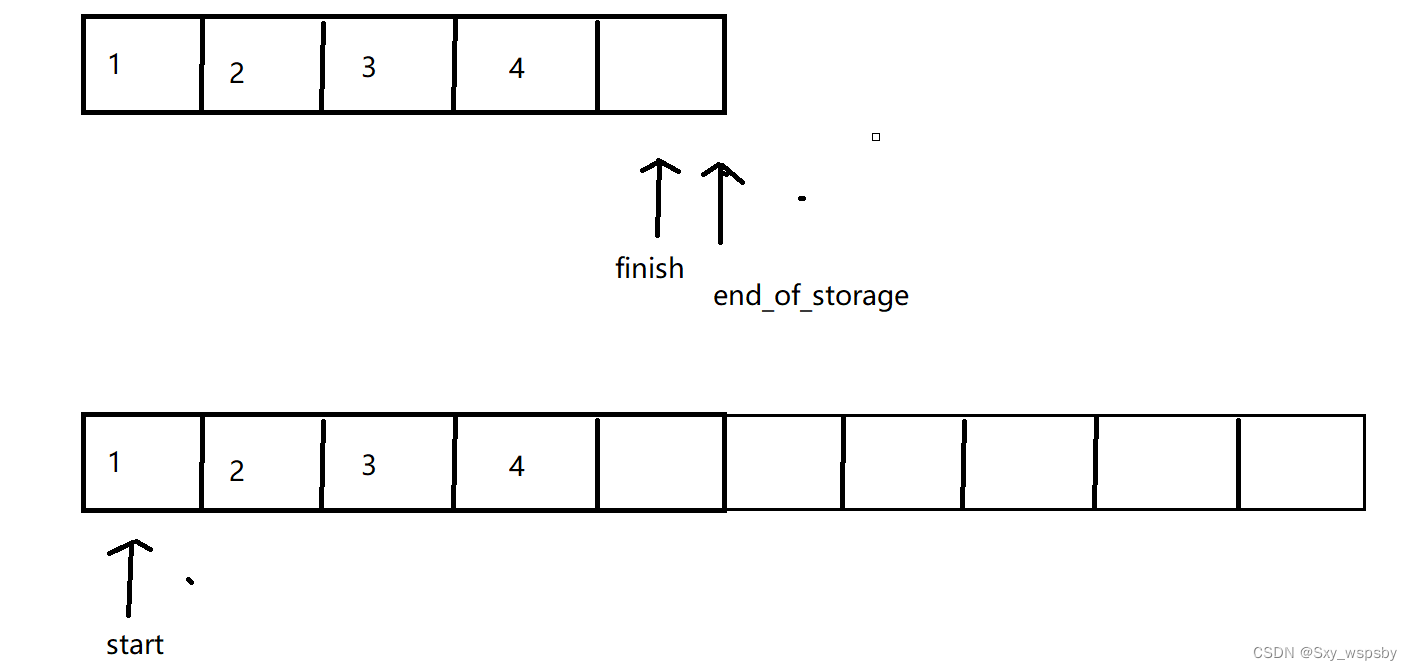
我们很明显的看到两个指针都不在同一块空间上,计算出来的size()不知道有多大,也就是说将新空间交给start后原先的finish失效了计算不出来真实的size()了,这个时候我们就需要提前记录size(),由于finish的位置是start+size()所以我们提前记录size()。而end_of_storage的位置也变了,在这里一定要注意end_of_storage = _start + n而不是end_of_storage = _start + capacity,因为我们扩容空间已经将空间改变了。
实现了push_back后我们就可以实现pop_back了,pop_back就非常的简单了:
- void pop_back()
- {
- assert(!empty());
- --_finish;
- }
尾删我们只需要让finish--向前移动一个位置即可,这个时候我们写的empty就派上用场了,我们尾删一定不可以一直让finish--,所以只有当不为空时才可以尾删。
下面我们实现一下迭代器,迭代器的实现与string没有很大的差别:
- namespace sxy
- {
- template<class T>
- class vector
- {
- public:
- typedef T* iterator;
- typedef const T* const_iterator;
- iterator begin()
- {
- return _start;
- }
- iterator end()
- {
- return _finish;
- }
- const_iterator begin() const
- {
- return _start;
- }
- const_iterator end() const
- {
- return _finish;
- }
- private:
- iterator _start;
- iterator _finish;
- iterator _end_of_storage;
- };
- }
同样我们要实现普通迭代器和const迭代器,这里与string无任何差别就不在介绍了。
接下来是resize接口,resize与string中的一样,当要开的空间小于capacity,就会将多余的数据删掉,当要开的空间大于capacity的时候,就要开空间并且初始化。
- void resize(size_t n, T val = T())
- {
- if (n < size())
- {
- _finish = _start + n;
- }
- else
- {
- if (n > capacity())
- {
- reserve(n);
- }
- while (_finish != _start + n)
- {
- *_finish = val;
- ++_finish;
- }
- }
- }
当开的空间小于size()的时候我们就删掉多余的空间,这里为什么是小于size()而不是小于capacity呢?我们看下图:
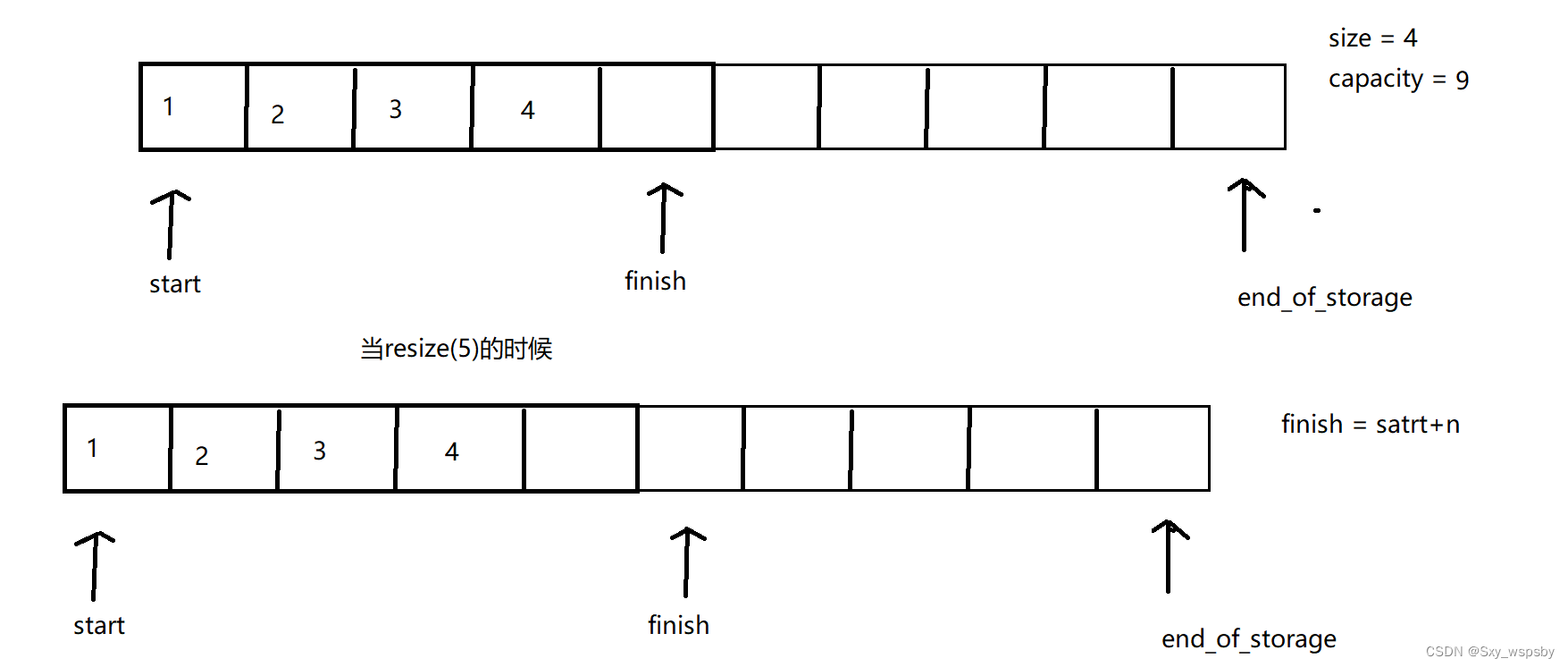
我们可以看到如果开的空间小于capacity就删除数据就会有这样的问题,finish往后移动了而实际的数据不仅没删还多出了空白空间,而用size()就不会发生这个问题,当开的空间小于size()的时候我们直接将finish移到start+n的位置,如下图:
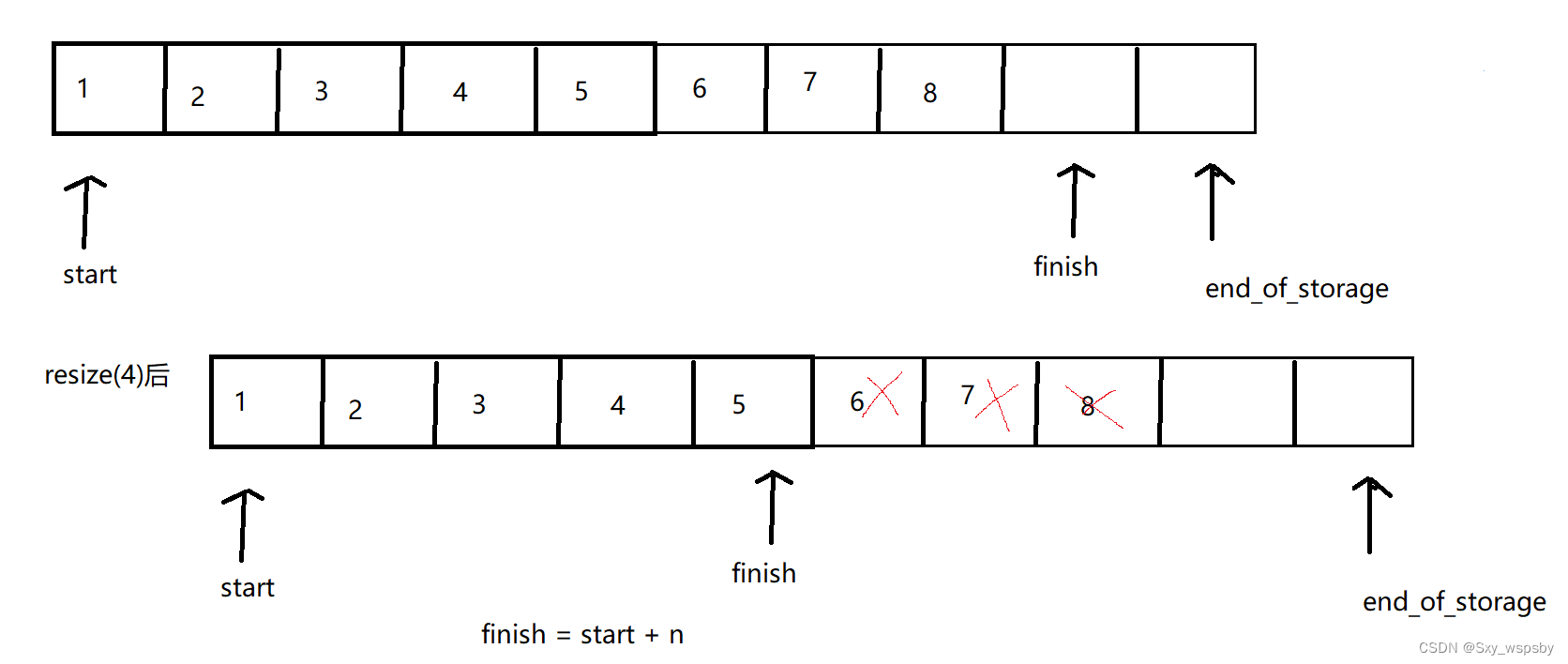
当要开的空间大于capacity的时候我们就扩容,扩容后从finish的位置开始填要初始化的数据,这里要初始化的数据不可以给0,因为很有可能vector里面放的自定义类型,自定义类型必须用其构造函数进行初始化,所以大家可以看到val的缺省值我们给的是T(),这个我们之前讲过这是一个匿名对象。
接下里介绍vector的重点insert接口和erase,为什么是重点呢?因为这两个接口会引起经典的迭代器失效问题。
- iterator insert(iterator pos, const T& val)
- {
- assert(pos >= _start);
- assert(pos <= _finish);
- if (_finish == _end_of_storage)
- {
- size_t len = pos - _start;
- reserve(capacity() == 0 ? 4 : 2 * capacity());
- //如果扩容pos指针将会失效所以需要重置pos的位置
- pos = _start + len;
- }
- iterator end = _finish - 1;
- while (end >= pos)
- {
- *(end + 1) = *end;
- --end;
- }
- *pos = val;
- ++_finish;
- return pos;
- }
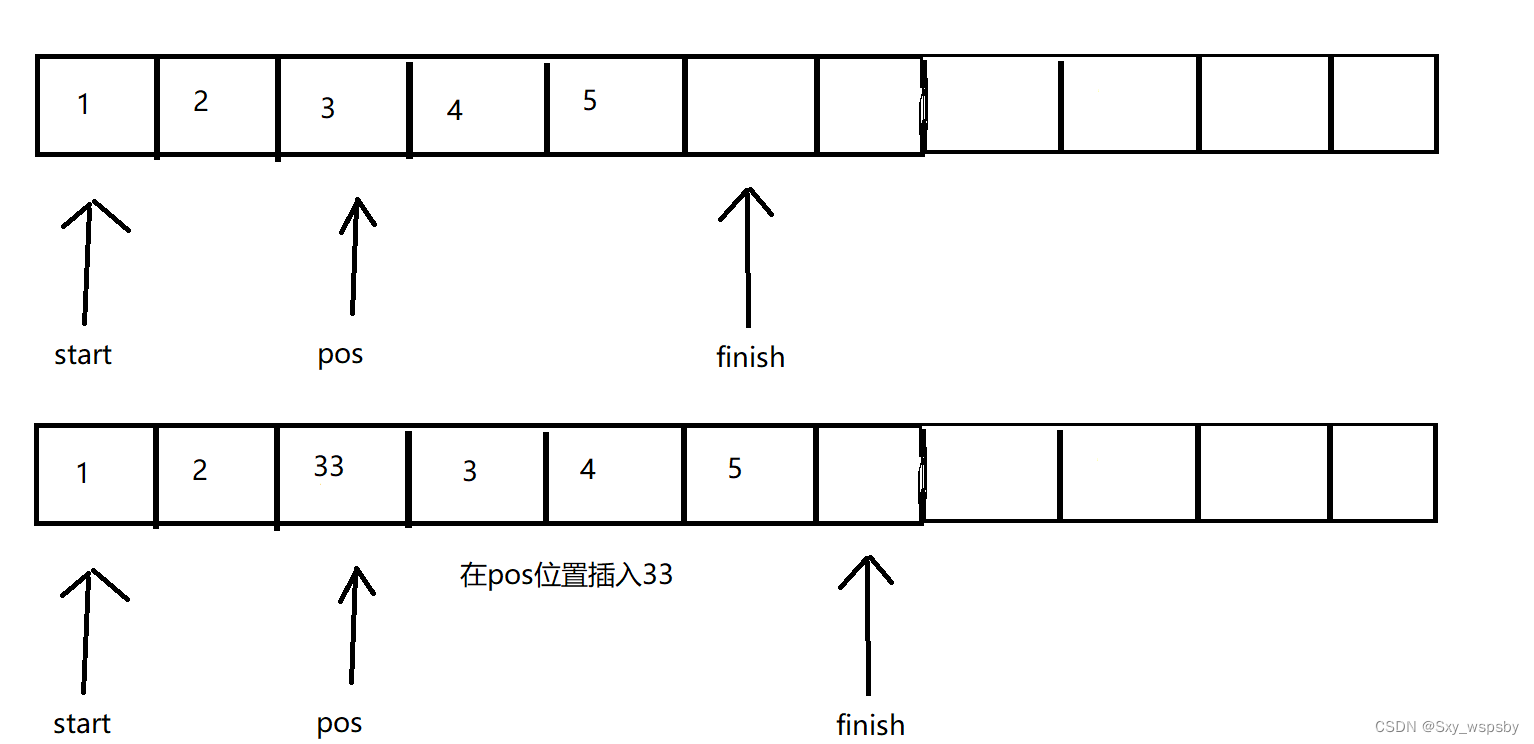
我们实现的insert只有从pos位置插入一个值即可,当然插入是有条件的不能随便插入,只有当要插入的位置大于等于start位置,小于等于finish位置才可以插入,等于start位置是头插,等于finish位置是尾插,当finish等于end_of_storage的时候我们就扩容,这里先不解释为什么要记录len等会我们画图解释一下,插入很简单,我们只需要让一个指针指向最后一个数据的位置,当end大于等于pos位置我们就把end位置上的数据放在end+1的位置上,然后让end--,当所有数据移完后我们就将要插入的数据放到pos位置,然后让finish++即可。如下图:
下面我们讲解失效问题,从上面代码大家应该也看出来了,失效只出现在扩容后如下图:
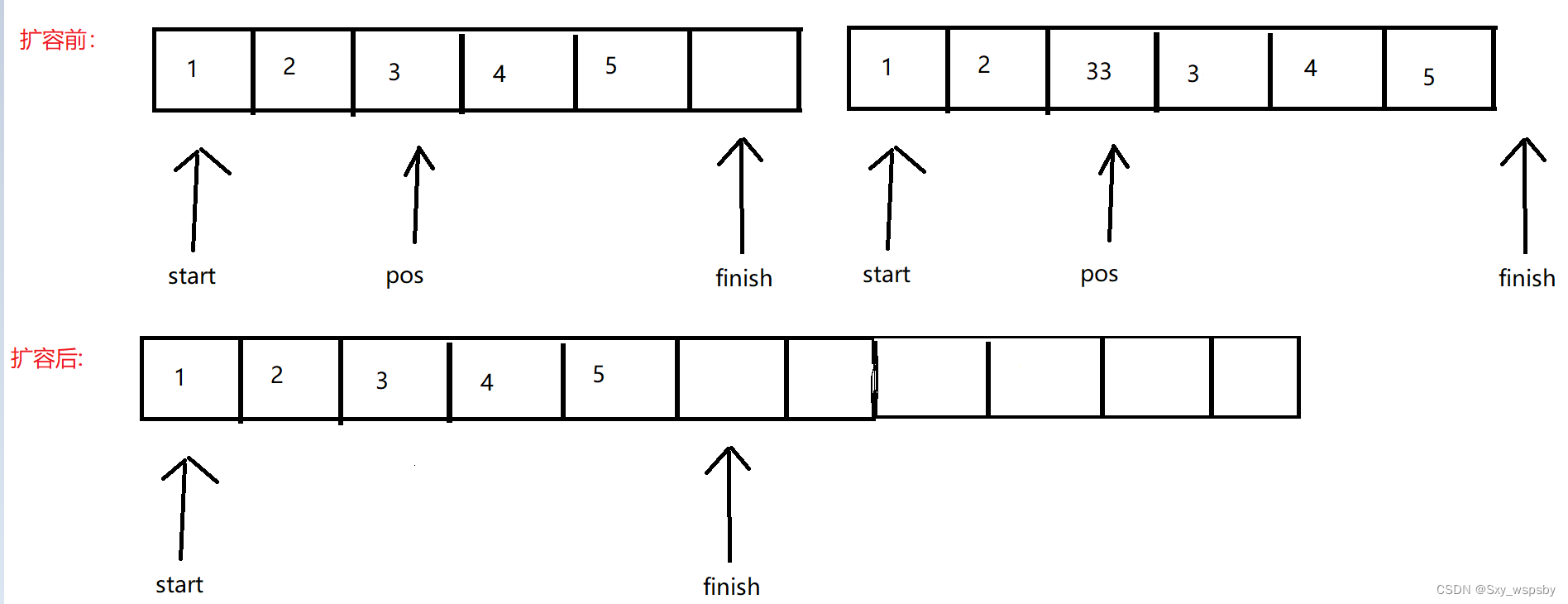
当我们扩容后start finish end_of_storage这三个指针都到了新空间上,而pos指针还指向旧空间,如果这个时候我们再往这个pos位置插入数据呢?答案显而易见,原先的那块空间都已经释放了再插入数据不就非法访问了吗,所以我们再扩容前先用len变量记录了pos的位置,然后在扩容后重置pos位置。
大家看下面这段代码的结果:
- void test6()
- {
- vector<int> v1;
- v1.push_back(1);
- v1.push_back(2);
- v1.push_back(3);
- v1.push_back(4);
- v1.push_back(5);
- for (auto ch : v1)
- {
- cout << ch << " ";
- }
- cout << endl;
- v1.insert(v1.begin(), 0);
- auto pos = find(v1.begin(), v1.end(), 3);
- if (pos != v1.end())
- {
- v1.insert(pos, 30);
- }
- for (auto ch : v1)
- {
- cout << ch << " ";
- }
- cout << endl;
- (*pos)++;
- for (auto ch : v1)
- {
- cout << ch << " ";
- }
- cout << endl;
- }
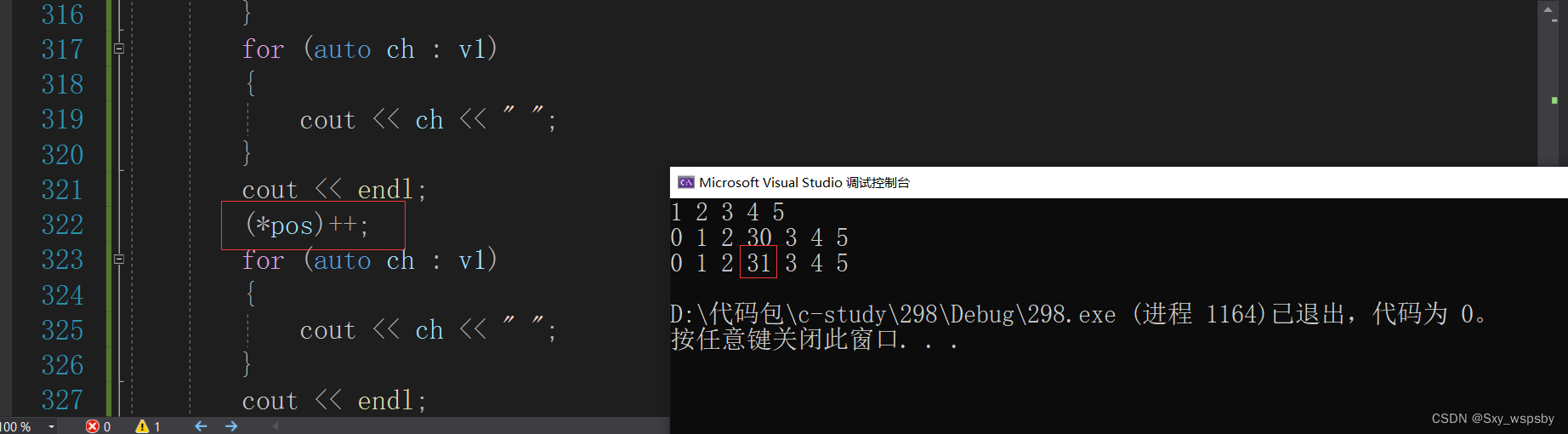
我们的目的是在3的位置++,按道理应该是0 1 2 30 4 4 5才对,为什么加的是30这个位置呢?这是因为形参不能改变实参,我们在insert函数里面虽然已经更新了pos位置,但是insert函数内部的pos是形参是一份临时拷贝根本不会影响到test6()中的pos位置,这个pos位置还是指向原先那个位置的。那么如何解决这个问题呢?我们只需要让其insert多一个返回值返回pos位置即可。那么我们既然想要函数内改变引起函数外的改变为什么不用引用传pos呢?如果用引用这里是会报错的,iterator我们设计的时候是传值返回,传值返回会临时拷贝一个对象,临时对象具有常性是不能用引用的。
下面我们讲解erase接口:
- iterator erase(iterator pos)
- {
- assert(pos >= _start);
- assert(pos < _finish);
- iterator end = pos + 1;
- while (end != _finish)
- {
- *(end - 1) = *end;
- ++end;
- }
- --_finish;
- return pos;
- }
erase的接口实现起来很简单,首先判断要删除的位置是否大于等于start并且小于finish。然后我们用一个指针指向pos+1的位置,只要end不等于finish我们就将end位置的值放入end-1的位置,移完数据后让finish--即可,这里要向insert一样返回pos位置,如下图:
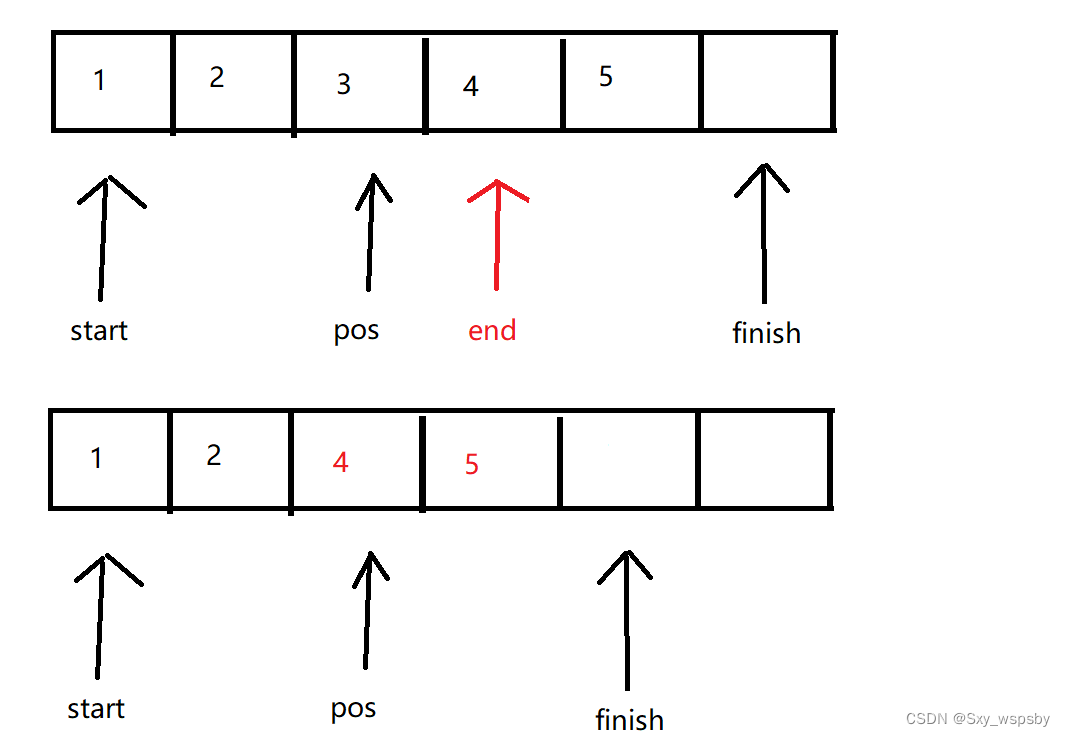
那么在什么情况下erase会导致迭代器失效失效呢?如下图:
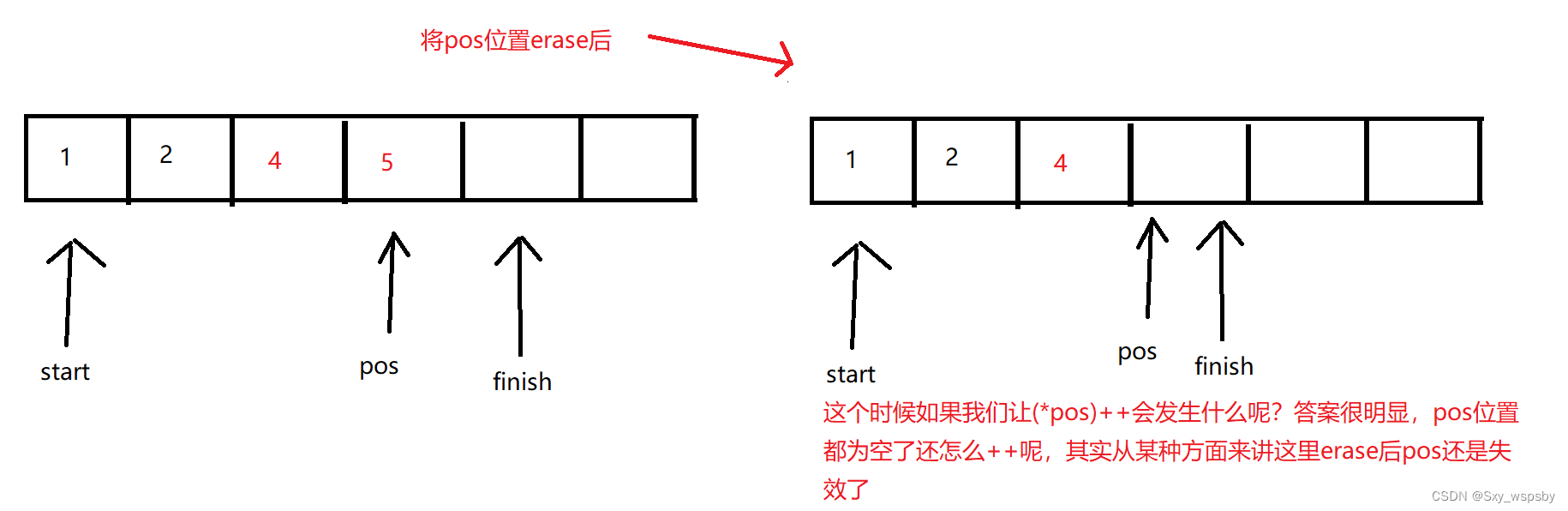
通过上面的图片我们应该了解了迭代器失效问题,下面我们讲几个简单的接口:
- void swap(vector<T>& v)
- {
- std::swap(_start, v._start);
- std::swap(_finish, v._finish);
- std::swap(_end_of_storage, v._end_of_storage);
- }
与某个vector<T>类型的对象交换,我们传参传的是引用,直接用库中的swap即可,将指针交换指向即可。
析构函数:
- ~vector()
- {
- delete[] _start;
- _start = _finish = _end_of_storage = nullptr;
- }
析构我们直接delete掉start的空间,然后将三个指针置为空。
拷贝构造函数:
- vector(const vector<T>& v)
- {
- _start = new T[v.capacity()];
- for (size_t i = 0; i < v.size(); i++)
- {
- _start[i]=v._start[i];
- }
- _finish = _start + v.size();
- _end_of_storage = _start + v.capacity();
- }
对于拷贝构造,我们直接给start开capacity大小的空间,然后将v中的数据依次挨个赋值给start,将数据都传到start后我们要将finish放在start+ size()的位置,然后将end_of_storage的位置放在start+capacity()的位置。
拷贝构造我们实现了后赋值就非常简单了。
赋值运算符重载:
- vector<T>& operator=(vector<T> v)
- {
- swap(v);
- return *this;
- }
我们直接传值传参,这样就会调用拷贝构造函数生成一份临时拷贝,然后用这份临时拷贝和*this交换,交换后*this就拥有了与v同样的数据,然后我们直接返回*this即可,这里既然我们要swap就一定不要穿引用传参,因为传引用会改变v的值,而赋值操作符是不会改变右边操作数的值的。
用n个val初始化的构造函数:
- vector(int n, const T& val = T())
- :_start(nullptr)
- , _finish(nullptr)
- , _end_of_storage(nullptr)
- {
- reserve(n);
- for (size_t i = 0; i < n; i++)
- {
- push_back(val);
- }
- }
首先我们在初始化列表将三个指针初始化为空指针,然后提前开n个大小的空间,然后依次将初始化的valpush_back到空间中,这里我们用的依旧是匿名对象做缺省值。
迭代器构造函数:
- template<class InputIterator>
- vector(InputIterator first, InputIterator last)
- {
- while (first != last)
- {
- push_back(*first);
- ++first;
- }
- }
迭代器的构造函数为什么我们用重新弄一个模板呢?这是因为我们用迭代器初始化不是一定要用vector的迭代器去初始化,我们还可能用string的迭代器去初始化,所以这里为了能使用各种迭代器我们直接弄一个迭代器模板,当first不等于last我们就push_back数据,然后让first++即可。
下面我们再来详细的讲解一下深拷贝问题:
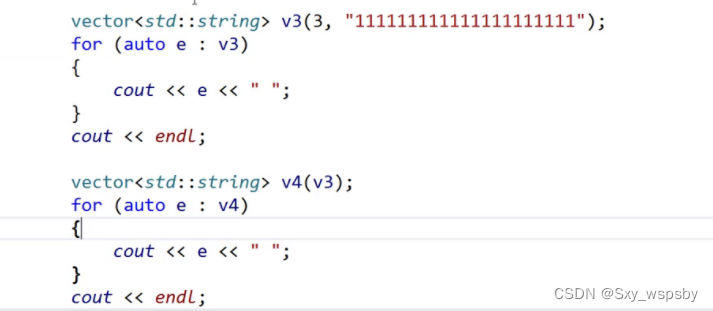
如上图所示的代码,如果我们用memcpy浅拷贝去扩容,去拷贝构造会发生什么呢?
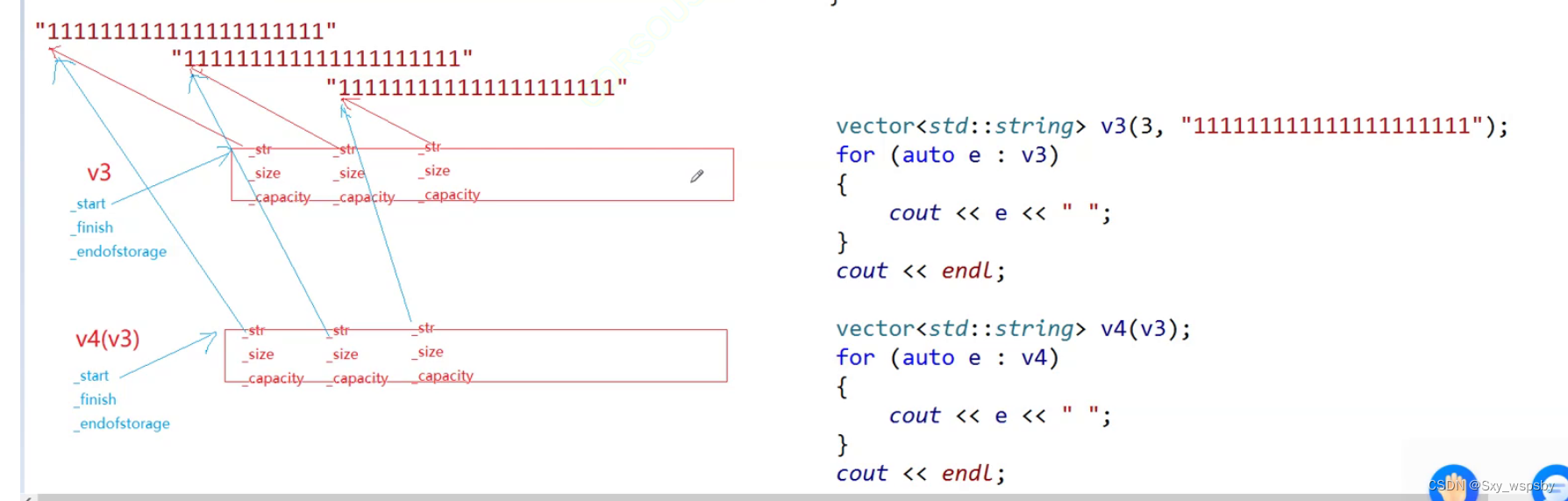
这个时候虽然vector的两个对象不在同一块空间,但是vector的每个string对象却指向了同一块空间,那么为什么我们用memcpy不行,用挨个赋值的方式就可以呢?这是因为string中对于赋值的运算符重载是深拷贝,是会给被赋值的对象先开好空间再将数据依次放入空间中,而我们的vector在扩容,拷贝构造函数中都用依次赋值的方法,只有我们将赋值运算符重载了变成深拷贝了才能解决vector的浅拷贝问题。下图是挨个赋值后的样子:
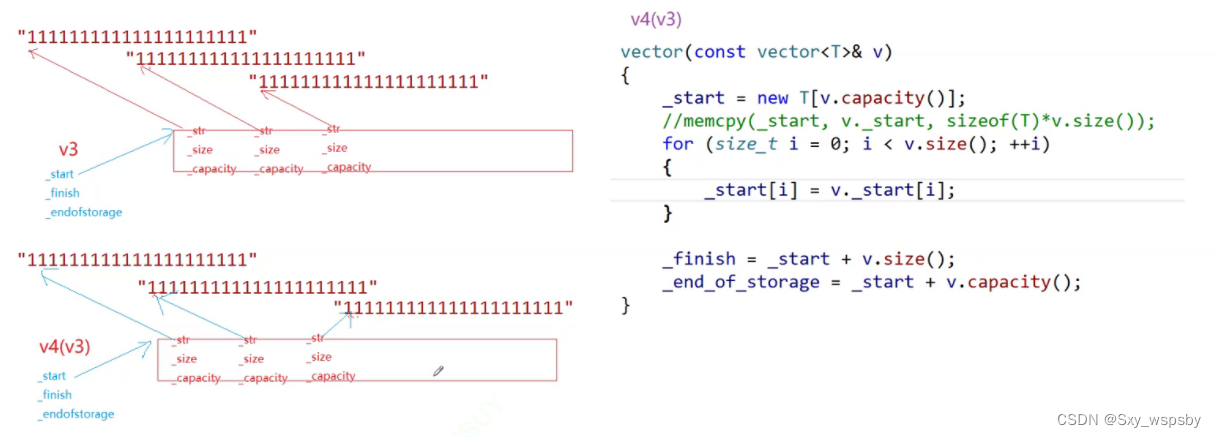
这样我们就将vector模拟实现完成了。
总结
vector的模拟实现相对于string来说会稍微难一些,不知道大家会不会有疑问,为什么string没有迭代器失效问题呢?因为我们访问string是采用下标的形式,而vector用的是指针。对于vector,我们学的重点就是迭代器失效问题以及深浅拷贝问题,这里尤其是深浅拷贝问题一不小心就会发现程序莫名其妙崩溃,对于vector的学习建议大家一定要多练习并且配合画图来理解。