作者|vivo 互联网服务器团队- Xu Shen
本文主要介绍vivo内部研发平台使用JaCoCo实现测试覆盖率的实践,包括JaCoCo原理介绍以及在实践过程中遇到的新增代码覆盖率统计问题和频繁发布导致覆盖率丢失问题的解决办法。
一、为什么需要测试覆盖率
1.1 在日常研发过程中,经常发现一些问题
- 测试案例的设计凭经验,当研发一个新功能时,经常对测试场景估计不足,到上线后发现bug;
- 开发经常做一些需求之外的代码变更(代码小范围内重构或在开发过程中发现小缺陷随手改掉),导致测试任务无法测试到对应的场景,引起线上问题;
- 对测试效果无法量化考核,导致测试工作的质量无法进一步提升。
1.2. 有没有技术手段能够尽可能的避免上面的问题呢?
在业内已经在普遍使用代码覆盖率来提升测试质量,那什么是代码覆盖率?
代码覆盖率是软件测试中的一种度量,描述程序中源代码被测试的比例和程度,所得比例称为代码覆盖率 。
代码覆盖率指标通常包含下面几类:
- 函数/方法覆盖率:函数/方法中有多少被调用到
- 分支覆盖率:有多少控制结构的分支(例如if语句)被执行
- 条件覆盖率:有多少布尔子表达式被测试为真值和假值
- 行覆盖率:有多少行的源代码被测试过
1.3 在使用测试覆盖率的过程中,经常发现的场景
- if/else语句中,if{}内的代码被覆盖到,else{}内的代码没有被覆盖到,可以得出部分分支场景没有测试到;
- try/catch语句中,try{}内的代码被覆盖到,catch{}内的代码没有被覆盖到,可以得出异常场景没有测试到;
- if (条件1 || 条件2 || 条件3)语句中,条件1被覆盖到,条件2和条件3没有被覆盖到,可以得出部分条件场景没有测试到;
测试人员对代码覆盖率的指标正确使用,能有效提升测试的质量,进而提升版本的上线质量。
二、JaCoCo在测试覆盖率场景中的使用
2.1 JaCoCo介绍
当前主流的代码覆盖率工具:
- C/C++→Gcov ,Java→JaCoCo,JavaScript→ Istanbul。
- 考虑到服务器端主要是Java语言,所以CICD平台优先使用JaCoCo来支持 Java 语言的代码覆盖率统计能力。
- 通过JaCoCo官网,我们可以看到JaCoCo的使命是为Java VM 的环境中的代码覆盖分析提供标准技术。重点是提供一个轻量级、灵活且有据可查的库,用于与各种构建和开发工具集成。
2.2 JaCoCo优点
- JaCoCo支持指令(C0)、分支(C1)、行、方法、类和圈复杂度等多维度的覆盖分析;
- 基于 Java 字节码,也可以在没有源文件的情况下工作;
- 性能良好,运行时开销很小,尤其是对于大型项目;
- 比较完整的API,很方便与其他工具进行集成;
- 远程协议和 JMX 控制可在任何时间点从代理请求执行数据下载。
2.3 JaCoCo原理
主要来自于JaCoCo官方网站
JaCoCo支持几种不同的方法来收集覆盖信息,对于每种方法,由不同技术实现的,下图橙色路径部分是JaCoCo 推荐使用的方式,即通过On-The-Fly方式收集覆盖率信息:
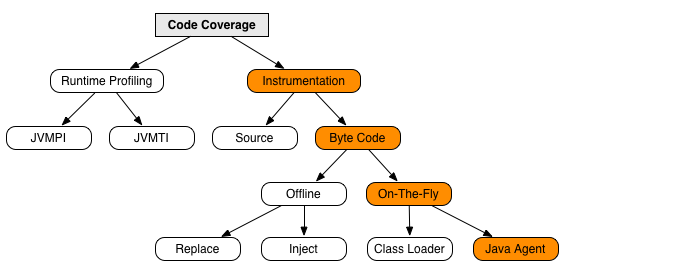
通过上图我们知道,JaCoCo 是通过对Java字节码(Byte Code)插入探针的方式来收集覆盖率信息的,探针是可以插入现有指令之间的附加指令。它们不会改变方法的行为,但会记录它们已被执行的事实。
下面以一段简单的 程序为例进行说明:

这段代码经过Java编译以后转化为以下字节码:

因为Java 字节码指令的线性序列,控制流是通过条件或无条件指令实现跳转的,跳转目标在技术上是相对于目标指令的偏移量。这个跟大学学习的汇编指令的跳转方式类似,为了更好的可读性,使用符号标签 (L1,L2 ) 代替实际的指令地址。

上图中橙色的部分为插入的探针,理论上我们可以在控制流图的每个边缘插入一个探针,由于探针实现本身需要一些字节码指令,这将会使类文件的大小增加数倍;幸运的是,这不是必需的,实际上我们只需要根据方法的控制流为每个方法插入几个探针。例如,没有任何分支的方法只需要一个探针。
如果已经执行了探测,我们就知道相应的边已经被访问过。从这条边我们可以得出结论到其他前面的节点和边:
如果一条边被访问过,我们就知道这条边的源节点已经被执行了;
如果一个节点已经被执行并且该节点是只有一条边的目标,我们知道这条边已经被访问过。
如果我们在正确的位置有探针,递归地应用这些规则可以确定方法的所有指令的执行状态,探针只是需要在控制流边缘插入的一小段附加指令。
三、CICD平台关于测试覆盖率的解决方案
通过上面对JaCoCo原理的介绍,结合我们公司内部的研发流程,在CICD平台对代码覆盖率功能的设计如下:

从上面 CICD 平台对测试覆盖率的设计图,大概可以看出来,整个过程包含三个阶段
3.1 测试前
测试前由测试人员(开发人员/运维人员)在流水线上开启测试覆盖率功能,在流水线执行发布时,会在测试环境上下载JaCoCo Agent包,并在Java进程启动时配置JavaAgent参数;
在进程启动过程或启动之后,有class文件被加载时被Agent拦截,对class文件进行插桩处理,在必要的路径下插入探针(插入探针的原理在上一节已经介绍)。
3.2 测试中
在测试过程中,测试人员在测试环境执行测试案例(手动执行或自动化脚本),被调用到的代码会被探针记录下来,探针数据保存在Java进程的内存中。
3.3 测试后
测试人员可以多次发布测试环境,针对同一个分支的代码,可以合并多次测试的结果数据,形成全量的覆盖率数据;
在测试结束后,CICD平台通过JaCoCo的API,手动/自动下载(dump)覆盖率数据,合并(merge)历史覆盖率数据,生成测试覆盖率报告;
测试人员根据测试覆盖率报告的结果,查看测试遗漏的场景,进行补充测试,事后总结遗漏的原因,提高测试效率。
四、在实践过程中遇到的问题及解决办法
测试覆盖率在上线运行一段时间后,在实践过程中发现了一些问题,总结为以下几点:
4.1 在不同机器编译会导致classid不一致的问题
在实践过程中,经常遇到这样一个问题,用户反馈并确认案例已经正常执行,但是生成的报告显示未覆盖,经过调查发现在测试环境中的class和生成报告时的class不一致导致的。
在 JaCoCo内部,覆盖率数据是以classid作为key来存储的,classid是根据class的字节码hash算法得出来的,看JaCoCo源码中关于classid的算法如下:

出现不一致的情况包括:
- 发布时编译的机器和生成报告的机器环境上有差异,比如操作系统版本、JDK版本等,导致编译的class不一致;
- 发布时编译的代码版本与生成报告时的代码版本有差异,导致编译的class不一致。
要解决上面环境的问题,需要保持在测试覆盖率过程中编译的机器环境保持一致,或者做到只编译一次,使用同一份class文件,考虑到存储空间的问题,vivo采用保持环境一致的办法来解决。
对于第二种情况,常见于采用敏捷研发的团队,在一个版本中按功能点转测,经常导致测试在测试过程中,源代码已经发生了修改,生成报告时代码版本和发布时的代码版本已经不一致,这种情况比较复杂,我们在下面会介绍。
4.2 在研发过程中更加关注增量代码的覆盖率
在我们日常的研发活动中,对于全量代码更多使用自动化脚本来回归,而新研发的功能主要表现为增量代码,对于增量代码的覆盖率情况更加关注, JaCoCo本身不支持增量代码的覆盖率。
对于这个问题网上也有不少解决方案,基本都是基于git的版本差异,在生成报告时过滤掉没有差异的类,形成两份覆盖率报告,一份是全量代码覆盖率报告,一份是增量代码覆盖率报告,而我们更希望在一份覆盖率报告中呈现增量代码和全量代码的覆盖情况,结合代码在全量报告中的覆盖路径分析遗漏的场景,同时能在报告中标注增量代码和增量代码的覆盖情况,期望的效果如下图所示:


为了达到上述效果,需要几个改造步骤:
- 计算出当前代码分支的变动情况,需要精确到代码行
- 改造JaCoCo计算逻辑,针对增量代码单独统计覆盖率指标值
- 改造JaCoCo报告格式,在报告中兼容全量代码和增量代码的覆盖情况
对于计算代码分支的变动情况,放弃 GitLab 提供的代码比对功能来获取不同版本之前的差异信息,如果版本之间差异太多的话,经常发生GitLab 的API接口调用超时;
并且GitLab 的比对功能无法满足定制场景,比如一行代码仅仅因为格式化被识别为变更代码等等,采用借助Linux自带的diff命令,实现代码差异比对的能力:

对于改造 JaCoCo计算逻辑,增加针对增量代码的覆盖率指标统计,在CoverageNodeImpl类中增加新的Counter,用于统计新增类、方法、行、指令覆盖率指标;在SourceNodeImple类中increment方法中增加新增代码行的统计逻辑。


4.3 重谈关于classid的问题
在上面已经谈到关于classid的问题,如果是环境问题是比较好解决,但是现在互联网团队基本都使用敏捷模式,基本不太可能等开发工作全部完成再转测,这样必然会导致最新的覆盖率报告,会出现以类为单元的覆盖率数据丢失,需要测试人员来回重复的执行测试案例,否则测试覆盖率数据不会很好看。
既然知道问题所在,那有没有办法解决呢?是不是可以直接找到以前的classid,把以前的classid对应的探针数据复制到当前的classid下就可以?当然是不行的,因为源代码发生变动,导致探针的数量发生变化,会出现下面的情况:

或者这样

出现这样的情况,会无法判断具体哪些探针是新增的或者删除的;即使出现前后探针一致的情况,也有可能因为代码修改,探针位置发生变化:

那么这个问题是否就无解了呢?这里给出一个大概思路,现在的覆盖率数据是以类为单位存储的,我们可以修改存储的粒度,细化到方法级别,这样可以保留一个类的大部分探针数据,这样如果只是修改一个方法的话,那么其他方法的测试数据可以继续保留,只需要重新测试这个方法就行,这样可以有效的降低测试人员对整个类的所有方案重复测试的情况。
五、总结
对于测试覆盖率功能,有没有给测试的质量带来提升,答案是显而易见的。
当然也因为上面提到的问题,给测试人员带了些麻烦,为了提升测试覆盖率数据,导致测试人员对同一个功能重复多次测试;同时也给测试人员带来了好处,很多测试人员在面对测试覆盖率指标严格要求下,被迫去看代码的实现逻辑,提升了自己业务水平和阅读代码的水平,甚至出现测试人员和开发人员当面对质,关于代码逻辑是否合理的场景。
最后,测试覆盖率不是衡量测试质量的唯一标准,要合理利用测试覆盖率来提升测试质量。