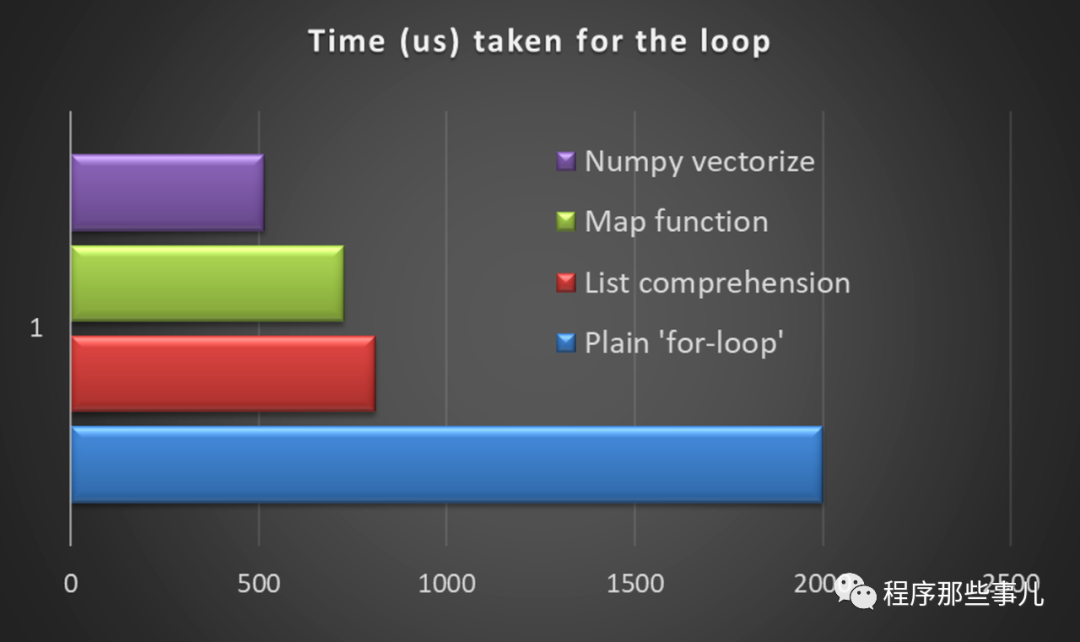
##使用循环
import time
start =time.time()
# iterative sum
total =0
# iterating through 1.5 Million numbers
for item in range(0,1500000):
total = total + item
print('sum is:'+ str(total))
end =time.time()
print(end - start)
#1124999250000
#0.14 Seconds
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
## 使用矢量化
import numpy as np
start =time.time()
# vectorized sum - using numpy for vectorization
# np.arangecreate the sequence of numbers from0 to 1499999
print(np.sum(np.arange(1500000)))
end =time.time()
print(end - start)
##1124999250000
##0.008 Seconds
import numpy as np
# 设置 m 的初始值
m = np.random.rand(1,5)
# 500 万行的输入值
x = np.random.rand(5000000,5)
1.
2.
3.
4.
5.
6.
## 使用循环
import numpy as np
m = np.random.rand(1,5)
x = np.random.rand(5000000,5)
total =0
tic =time.process_time()
for i in range(0,5000000):
total =0
for j in range(0,5):
total = total + x[i][j]*m[0][j]
zer[i]= total
toc =time.process_time()
print ("Computation time = "+ str ((toc - tic))+"seconds")
####计算时间 =27.02 秒