作为一名前端,开发web页面是我们的本职工作。在完成一个页面开发的过程中,保存代码然后手动刷新页面查看效果,这样的动作需要重复无数次,虽然一次这样的动作可能只要花费几秒钟的时间,但是次数多了也挺浪费时间的。
社区有一款工具可以帮助前端在每次保存完代码后自动刷新浏览器页面——livereload。
自动刷新工具
目前有很多的工具都内置了自动刷新功能,以下列举几个常见的。
- 浏览器插件liveReload
- webpack的webpack-dev-server模块
- gulp的gulp-livereload模块
- grunt的grunt-livereload模块
- 全局模块puer
这样的工具有很多,个人觉得最方便的要数puer,只要全局安装并在工程根目录下运行即可,效果如下。
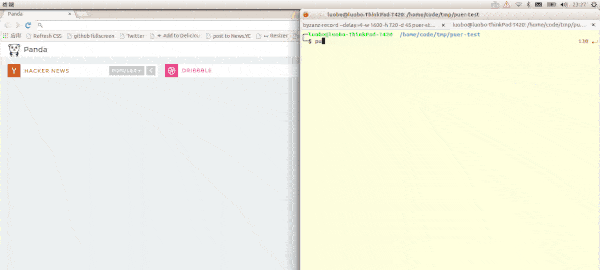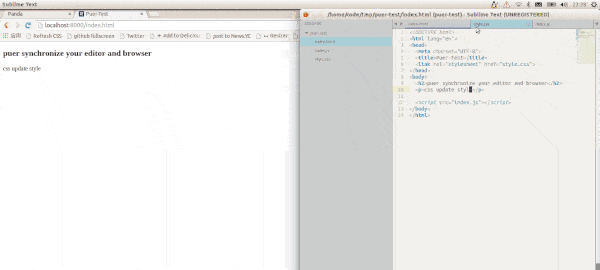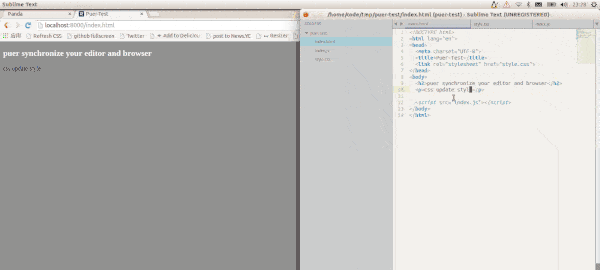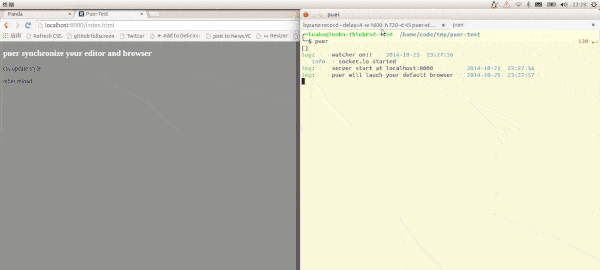
图1
自动刷新原理
社区里大多数的自动刷新工具都是使用livereload实现的,下面我们就分析一下它的内部原理是什么?
场景:当在编辑器中修改文件内容并保存时,浏览器自动刷新页面;
分析:监听文件的修改,并且把修改的动作通知浏览器。监听操作可以用chokidar模块完成,通知操作可以用websocket来做。
根据以上的分析,我们要搭建一个小服务器,这个服务器可以访问被修改的文件、监听文件修改以及与浏览器通信。
浏览器这边通过websocket接收服务器传来的指令来刷新页面内容,页面刷新的逻辑可以封装在livereload.js中,这是一个单独的js文件,可以由html文件引入。
整个流程如下图。

图2
自动刷新实现
1、服务端代码实现
1)搭建服务器

图3
启动图3中的服务,通过localhost:3000可以访问图左侧html和css两个文件,这两个文件代表需要开发的代码。
2)再搭建一个服务器,用于页面访问livereload.js

图4
此处用于图7中html引入livereload.js。
3)搭建websocket服务器
本文搭建websocket服务器不再一步步手写,而是直接采用ws模块,如下:

图5
图5中封装了一个send方法,用于向页面发送刷新通知。
4)监听代码文件的变化

图6
chokidar模块监听代码文件的变化,其监听的目录和参数配置可以自定义。filterRefresh调用了图5中定义的send函数,用于发送指令,指令的数据格式也可以自定义,只要页面能解析出来即可。
2、浏览器端代码实现
1)开发页面中引入livereload.js

图7
这一步在webpack、fis3等构建工具中都是自动化插入的,无需手动操作。
2)livereload.js中实现websocket连接

图8
此处页面接收来自服务器的指令,然后把它解析出来执行即可。核心指令当然是reload,但是不同的资源刷新的方式有所不同,下面会详细介绍。
3)直接刷新页面

图9
4)刷新chrome插件

图10
5)更新img标签中的图片

图11
document.images可以获取文档中所有图片的dom对象,将每个图片地址加一个版本号即可刷新。
这里获取的图片可能不是本次修改的,那么如何获取当前被修改的文件呢?
如果图片是自动刷新服务的资源,那么它的src应该是localhost:3000/图片的路径/图片名称。
图6中websocket传给页面的数据中包含了文件在代码目录下的路径,如果被监听的目录下的图片被修改,那么它的路径(/home/用户名/图片的路径/图片名称)和src会有一段重合的部分,反之,就不会有重合的部分。这里就用这个小技巧来排除不需要更新的图片。
6)更新行内样式中的背景图

图12

图13
document.querySelectorAll(`[style*=${selector}]`)可以获取拥有style属性的dom,然后通过dom对象的style属性可以获取style属性包含的样式,再通过具体的css样式属性就可以获取具体的样式的值,最后通过正则将背景图匹配出来并加上版本号。

图14
7)更新内嵌和外链样式中的背景图

图15

图16
document.styleSheets可以获取所有的内嵌和外链样式,再通过cssRules和style属性可以获取一组样式表,剩下的处理就和图13一致了。
注意:如果遇到了import或者媒体查询media,需要做递归获取样式表,这里就不再嗷述了。
8)更新外链样式(不包含import)

图17
document.getElementsByTagName('link')可以获取所有的外链css,通过path和href的对比可以过滤出本次修改的css文件,然后将外链css的href加上版本号并重新生成一个link标签插在之前外链样式之后,待新css资源加载完成就可以删除之前的css资源了。
8)更新外链中import中的样式

图18
document.querySelectorAll('link')[i].sheet.cssRules[i].href 这样的写法可以获取到import进来的css的url。

图20
总结
浏览器自动刷新功能需要服务端和浏览器端配合实现,服务端的实现比较简单,最大的难点在于浏览器端对css的操作。如果每次只是暴力的刷新整个页面,不考虑对精准资源的刷新,可能无法保持页面中已存在的一些状态。
现在有条件的公司一般都会给程序员配备一台mac加一个大屏显示器,就像下面这样。

图21
一个屏幕打开编辑器,另外一个屏幕打开浏览器,保存代码后只要转一下头就能看见页面刷新,不用再在一个屏幕上切来切去,开发效率直线上升。
自动刷新的原理也是一个面试题,如果你理解了上面的实现原理,以后再碰见这道题,肯定so easy!